
PySpark - Module 0.0: Course Overview
Learn pyspark, for Data Science and Data Engineers (in Databricks)

PySpark - Module 0.1: Getting Started on Databricks
Create a free Databricks account and confirm your setup before the first session

PySpark - Module 1: Big Data and Apache Spark
Learn pyspark, Introduction to Big Data and Apache Spark
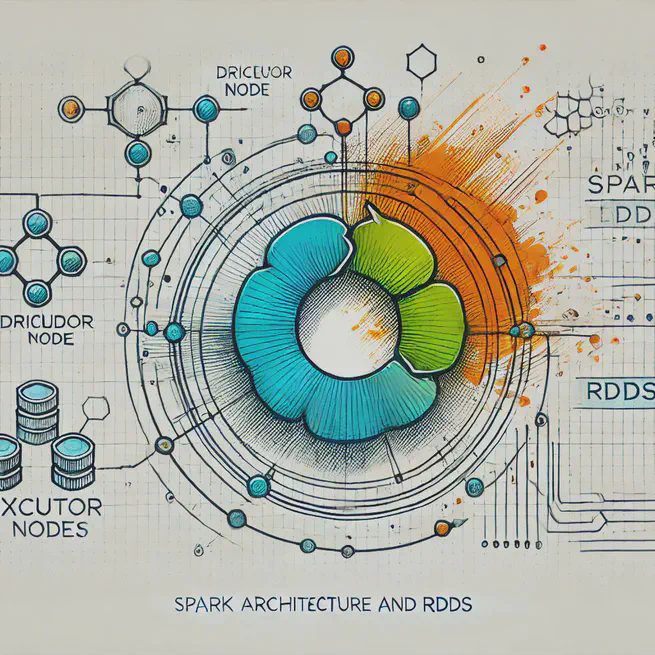
PySpark - Module 2: Spark Architecture and RDDs
Learn pyspark, Spark Architecture and RDDs
PySpark - Module 3: DataFrames and Spark SQL
Learn pyspark, DataFrames and Spark SQL (in Databricks)
PySpark - Module 4: Data Sources and Sinks
Learn pyspark, Data Sources and Sinks
PySpark - Module 5.0: Spark Streaming
Learn pyspark, Spark Streaming
PySpark - Module 5.1: Deploying Kafka
Deploying Apache Kafka on a Single Node
PySpark - Module 5.2: Kafka Producers and Consumers
Python-Based Producers and Consumers
PySpark - Module 5.3: Kafka and Structured Streaming
Apache Spark Structured Streaming
PySpark - Module 6.0: MLlib Fundamentals
MLlib fundamentals: the Pipeline API and feature engineering on Databricks
PySpark - Module 6.1: Supervised Learning at Scale
Supervised learning at scale: trees, ensembles, evaluation, and tuning with CrossValidator
PySpark - Module 6.2: Unsupervised Learning and Recommendation
Unsupervised learning and recommendation: K-Means clustering and ALS collaborative filtering
PySpark - Module 6.3: ML Pipelines in Production
ML pipelines in production: saving models, batch inference, MLflow tracking, and drift
PySpark - Module 6.4: H2O Sparkling Water
Scalable Machine Learning with H2O and Sparkling Water
PySpark - Module 6.5: Distributed ML with H2O
Introduction to Distributed Machine Learning
PySpark - Module 6.6: Running H2O Sparkling Water
Running H2O Sparkling Water (requires classic Databricks compute)
PySpark - Module 7: Capstone Project
The capstone: apply the full stack to a real problem, on one of two tracks
PySpark - Exercise: Reviewing AI-Generated Code
A hands-on exercise: find and fix the performance traps in an AI-generated Spark pipeline
PySpark - Tuning Essentials
Tuning essentials: reading the plan, partitioning, and caching, on serverless and classic